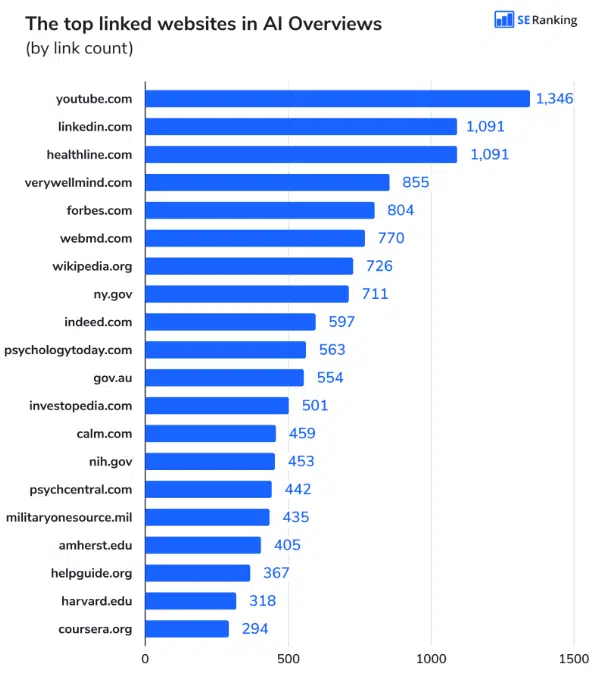
Optimisations SEO sur les LLMs – Comment se rendre visible sur les nouveaux moteurs de recherche

Alors que ChatGPT, Perplexity, Gemini et autres grands modèles de langage (LLMs) gagnent en popularité, les marques n’ont qu’une crainte : disparaître des moteurs de recherche. En fournissant des réponses directement à l’internaute, ces IA génératives perturbent la stratégie SEO de nombreuses entreprises.
Mais pour répondre à l’internaute en toute transparence, les LLMs doivent fournir leurs sources. Et c’est là que l’optimisation de l’IA générative entre en jeu. Avec ce référencement naturel nouvelle génération, vous pouvez devenir visible sur n’importe quel moteur boosté à l’intelligence artificielle. Décryptage.
Explorer l’IA générative et les grands modèles de langage
Pourquoi comprendre le TAL et les LLM est crucial :
Se familiariser avec le traitement du langage naturel (TAL) et les grands modèles linguistiques (LLM) est une étape essentielle pour anticiper les évolutions en matière de référencement, de branding numérique et de stratégies de contenu. Une compréhension approfondie de ces technologies permet d’en exploiter pleinement le potentiel.
Les idées présentées ici s’appuient sur une décennie de travail en recherche sémantique, des études approfondies dans la littérature scientifique et l’analyse des brevets liés à l’IA générative.
Fonctionnement des grands modèles linguistiques
Les bases des LLM
Avant d’adopter des outils comme GEO (Generative Engine Optimization), il est essentiel de comprendre les fondations technologiques des LLM. De la même manière qu’il est indispensable de maîtriser les moteurs de recherche pour éviter des pratiques inefficaces, investir quelques heures dans l’apprentissage de ces concepts peut permettre de gagner du temps et des ressources en écartant des stratégies peu pertinentes.
Les LLM : une avancée révolutionnaire
Les modèles de langage comme GPT, Claude ou LLaMA incarnent une transformation majeure dans la manière dont l’IA générative et les moteurs de recherche traitent les requêtes.
Ils ne se contentent pas de chercher des correspondances textuelles, mais génèrent des réponses nuancées et contextuellement riches, grâce à leurs capacités avancées en compréhension et raisonnement linguistiques. Par exemple, des recherches comme « Large Search Model: Redefining Search Stack in the Era of LLMs » de Microsoft soulignent leur rôle dans la refonte des technologies de recherche.
Fonctionnalités avancées des LLM en recherche
Les LLM adoptent une approche unifiée pour traiter toutes les tâches liées à la recherche comme des problèmes de génération de texte. Cela leur permet :
- De générer des réponses complètes : Ils produisent des synthèses en langage naturel, au-delà de la simple extraction d’informations.
- De personnaliser les réponses : Grâce à des invites spécifiques, les modèles adaptent leurs résultats aux besoins des utilisateurs.
- D’améliorer les requêtes : En cas de données insuffisantes, les LLM génèrent des requêtes supplémentaires pour collecter des informations plus pertinentes.
Les étapes clés du traitement par les LLM
Encodage : structurer les données
Les données brutes sont transformées en jetons, les unités fondamentales des modèles. Ces jetons représentent divers types d’informations (mots, entités, images, etc.) selon l’application.
Transformation des jetons en vecteurs
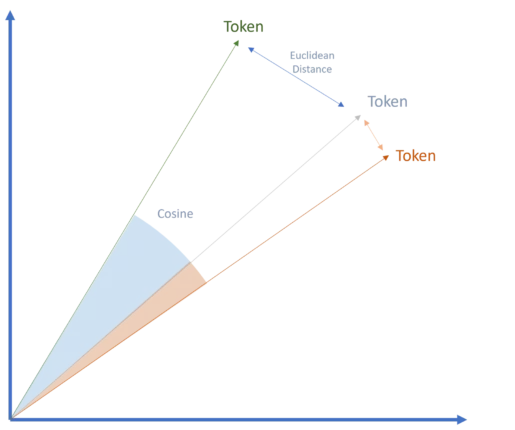
Les jetons sont convertis en vecteurs, une étape essentielle des modèles basés sur les transformateurs, comme la technologie de Google. Ces vecteurs, représentations numériques des jetons, capturent leurs attributs spécifiques et permettent de mesurer des relations sémantiques via des méthodes comme la similarité cosinus ou la distance euclidienne.
Cette approche basée sur les vecteurs et les transformateurs a révolutionné l’IA générative et reste un facteur clé de l’adoption massive des LLM aujourd’hui.
Le processus de décodage
Le décodage est l’étape où le modèle interprète les probabilités associées à chaque prochain jeton possible (mot ou symbole). L’objectif est de produire une séquence fluide et naturelle.
Les techniques de décodage
Pour atteindre cet objectif, plusieurs méthodes sont utilisées :
- Échantillonnage Top K : Considère les K mots les plus probables comme options pour la suite.
- Échantillonnage Top P : Prend en compte les mots dont les probabilités cumulées atteignent un certain seuil (P), permettant une plus grande variation.
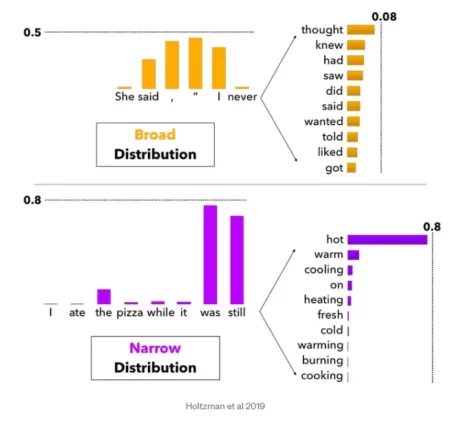
Ces méthodes influencent le niveau de créativité du modèle. Par exemple, un modèle « strict » favorise les options les plus probables, produisant des réponses cohérentes et prévisibles, tandis qu’un modèle « plus flexible » explore des alternatives, générant des réponses variées.
Diversité des sorties et créativité
Le choix de la méthode de décodage explique pourquoi une même invite peut produire des résultats différents. Avec une marge de créativité élargie, les modèles prennent en compte une gamme plus étendue de mots potentiels, ce qui favorise des réponses plus originales et nuancées.
Au-delà du texte : les capacités multimédias de l’IA générative
Bien que les processus d’encodage et de décodage soient principalement associés au traitement du texte, ils s’appliquent également à d’autres formats comme l’audio et les visuels. Ces contenus sont d’abord convertis en jetons textuels avant d’être traités par les modèles.
Pour les applications GEO, cette capacité multimédia est moins pertinente. Cependant, la fenêtre contextuelle élargie des LLM permet de mieux comprendre les relations entre les entités principales et secondaires dans les phrases, enrichissant ainsi les résultats produits.
Défis et solutions de l’IA générative
Les grands modèles linguistiques (LLM) doivent relever trois défis principaux :
- Mise à jour des informations : Éviter que les réponses ne soient obsolètes.
- Réduction des hallucinations : Garantir l’exactitude des réponses.
- Précision thématique : Fournir des informations détaillées sur des sujets spécifiques, et non des réponses génériques.
Pour y remédier, la génération augmentée par récupération (RAG) s’impose comme une solution efficace.
Génération augmentée par récupération (RAG) : fonctionnement et avantages
RAG enrichit les LLM en leur fournissant des données spécifiques à chaque sujet, intégrées sous forme de documents ou de vecteurs représentant des relations sémantiques complexes (comme dans les graphiques de connaissances).
Cette approche permet :
- Une meilleure compréhension des relations entre entités.
- Une précision accrue dans les réponses thématiques.
Applications et enjeux pour GEO
RAG offre des opportunités pour les outils comme GEO, en facilitant l’accès à des sources pertinentes et en permettant une personnalisation des données utilisées.
Cependant, le défi reste de déterminer comment les plateformes sélectionnent et évaluent la qualité des sources, un facteur clé pour assurer la pertinence et la fiabilité des réponses.
L’importance des modèles de récupération dans l’architecture RAG
Les modèles de récupération jouent un rôle fondamental dans les systèmes de génération augmentée par récupération (RAG), en agissant comme des « bibliothécaires spécialisés » capables d’identifier les informations pertinentes dans d’immenses ensembles de données.
Fonctionnement et avantages
Ces modèles utilisent des algorithmes avancés pour évaluer et sélectionner les données les plus utiles, intégrant des connaissances externes dans la génération de texte. Cela permet :
- Une production de contenu enrichie et contextualisée.
- Une extension des capacités des modèles linguistiques classiques.
Les systèmes de récupération s’appuient sur plusieurs technologies, notamment :
- Incorporations vectorielles et recherche vectorielle.
- Indexation de documents avec des techniques comme BM25 ou TF-IDF.
Variations et limites des approches de récupération
Tous les systèmes d’IA n’intègrent pas des mécanismes de récupération sophistiqués, ce qui pose des défis pour l’optimisation des architectures RAG.
- Meta : Développe son propre moteur de recherche pour ses modèles LLaMA, visant une meilleure maîtrise des données récupérées.
- Perplexity : Utilise des systèmes d’index et de classement propriétaires, bien qu’il soit parfois accusé de s’appuyer sur des résultats de moteurs comme Google.
- Claude (Anthropic) : Son utilisation de RAG reste peu transparente, combinant potentiellement des données utilisateur et son propre index.
- Gemini, Copilot et ChatGPT : Exploitent les moteurs de recherche de leurs partenaires (Microsoft Bing pour ChatGPT) ou développent des solutions propriétaires comme SearchGPT.
Cas de ChatGPT et SearchGPT
OpenAI a récemment introduit SearchGPT, combinant plusieurs technologies pour enrichir ses réponses :
- Un modèle basé sur une version affinée de GPT-4, entraîné avec des techniques de distillation de données synthétiques.
- Des partenariats avec des fournisseurs de recherche tiers (notamment Microsoft Bing) et des contenus directs de partenaires.
Bien que ChatGPT montre des similitudes avec les classements de Bing pour certaines requêtes, son modèle utilise des sources diversifiées, garantissant une certaine indépendance dans ses réponses.
Évaluation du pipeline RAG : critères clés
L’évaluation d’un système de génération augmentée par récupération (RAG) repose sur plusieurs métriques essentielles pour mesurer sa performance et sa fiabilité.
Critères d’évaluation principaux
- Fidélité : Vérifie la cohérence factuelle des réponses par rapport au contexte fourni.
- Pertinence de la réponse : Mesure dans quelle mesure la réponse générée correspond à l’invite.
- Précision du contexte : Évalue le classement correct des éléments contextuels pertinents, avec des scores de 0 à 1.
- Ancrage : Vérifie si les réponses sont directement étayées par les informations sources, garantissant leur vérifiabilité.
- Références sources : Assure la présence de citations et de liens pour faciliter la vérification.
- Répartition et couverture : S’assure d’une représentation équilibrée entre les différentes sources et sections consultées.
- Exactitude des faits : Vérifie la présence d’informations factuelles précises dans le contenu généré.
- Critères personnalisés (critique d’aspect) : Permet l’évaluation selon des aspects spécifiques, tels que l’exactitude ou l’innocuité.
Indicateurs de performance spécifiques
- Précision moyenne (MAP) : Moyenne des précisions calculées pour chaque requête, en tenant compte du classement des documents dans les résultats. Une MAP élevée reflète une meilleure pertinence des résultats de recherche.
- Rang réciproque moyen (MRR) : Mesure la rapidité avec laquelle le premier document pertinent apparaît dans les résultats. Un MRR élevé indique que les résultats les plus pertinents sont bien classés.
- Qualité autonome : Note de 1 à 5 qui évalue si le contenu généré est compréhensible sans contexte externe.
Différence entre invites et requêtes
- Requêtes : Souvent des mots-clés ou phrases courtes, elles ciblent des résultats spécifiques dans une recherche classique.
- Invites : Formulées en langage naturel, elles offrent un contexte plus détaillé et permettent des réponses plus nuancées.
Dans les systèmes RAG, l’invite est transformée en requête en arrière-plan pour interroger efficacement les bases de données tout en préservant le contexte initial, ce qui améliore la précision et la pertinence des réponses.
Optimisation des aperçus IA et assistants IA
- Aperçus IA (Google SERP) : Générés à partir de requêtes de recherche, ils fournissent des extraits directs en réponse.
- Assistants IA : Basés sur des invites complexes, ils offrent des réponses plus riches et contextualisées.
Pour combler l’écart entre les deux, RAG adapte les invites complexes en requêtes tout en conservant le contexte critique, garantissant une récupération optimale des sources pertinentes.
Objectifs et stratégies de GEO
Les objectifs du GEO (Global Entity Optimization) varient selon les ambitions des acteurs :
- Être cité dans des liens sources : Cette stratégie vise à inclure du contenu directement référencé dans les sources citées par les systèmes d’IA générative.
- Obtenir des mentions directes : Cela consiste à augmenter la probabilité que votre marque, produit ou nom soit intégré dans les réponses générées par l’IA.
Bien que ces objectifs soient complémentaires, ils nécessitent des approches distinctes. Dans les deux cas, il est essentiel d’établir une présence solide parmi les sources privilégiées ou fréquemment consultées par les modèles linguistiques.
Priorisation des modèles linguistiques
Chaque assistant d’IA utilise des critères spécifiques pour sélectionner et recommander des entités. Cela implique :
- Comprendre les mécanismes des LLM : Étudier les différences entre les grands modèles linguistiques comme Gemini, Copilot, ChatGPT ou Perplexity.
- Surveiller les marchés émergents : Identifier les applications qui dominent des secteurs ou régions spécifiques.
Pour les professionnels habitués à se concentrer sur Google, cela requiert un changement stratégique, intégrant une diversité de plateformes et un suivi constant des évolutions du marché.
Mentions et citations dans les réponses générées
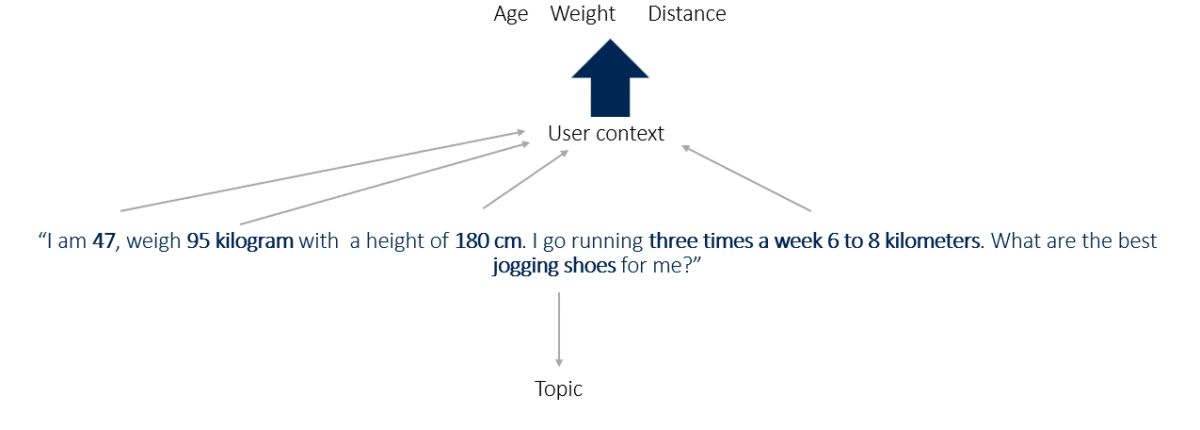
Les systèmes d’IA utilisent des attributs contextuels pour structurer leurs réponses. Par exemple :
Exemple d’invite :
« J’ai 47 ans, je pèse 95 kg, je mesure 180 cm et je cours 3 fois par semaine sur 6 à 8 kilomètres. Quelles sont les meilleures chaussures de jogging pour moi ? »
- Attributs contextuels : âge, poids, taille, fréquence et distance de course.
- Entité principale : chaussures de jogging.
Les produits ou services fréquemment associés à ces contextes bénéficient d’une probabilité accrue d’être mentionnés par les systèmes d’IA.
Insights sur la sélection des sources
Des plateformes comme ChatGPT ou Perplexity démontrent comment les systèmes d’IA identifient et citent des contenus en fonction des requêtes :
- Les titres de sources comme « Les meilleures chaussures pour les coureurs lourds en 2024 » ou « Les 7 meilleures chaussures de course longue distance » montrent que l’IA déduit des informations spécifiques des attributs de l’utilisateur.
Travailler en amont pour aligner son contenu sur les critères des assistants IA est donc crucial pour maximiser la visibilité et les mentions dans les réponses générées.
Copilote
Copilot analyse des attributs comme l’âge et le poids pour contextualiser les réponses.
À partir des données fournies, il peut déduire un contexte de surpoids en s’appuyant sur les sources référencées.
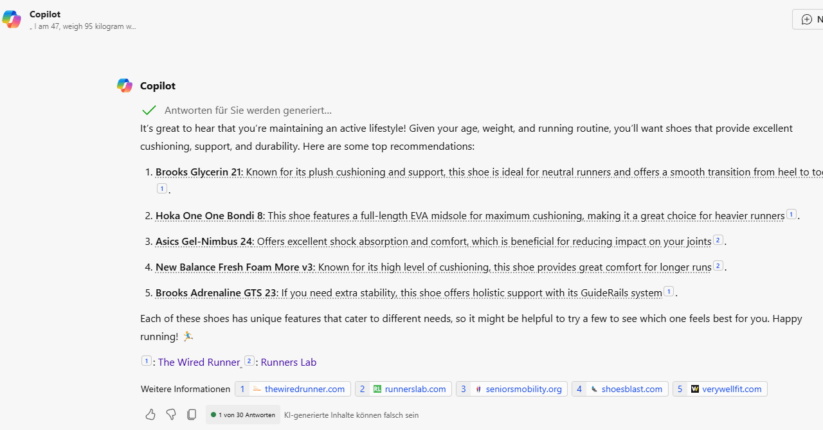
Les sources citées proviennent exclusivement de contenus informatifs, tels que des tests, des critiques et des classements, plutôt que de pages de commerce électronique ou de fiches produits détaillées.
ChatGPT
ChatGPT prend en compte des attributs comme la distance parcourue et le poids. En se basant sur les sources référencées, il en déduit un contexte de surpoids et de course longue distance.
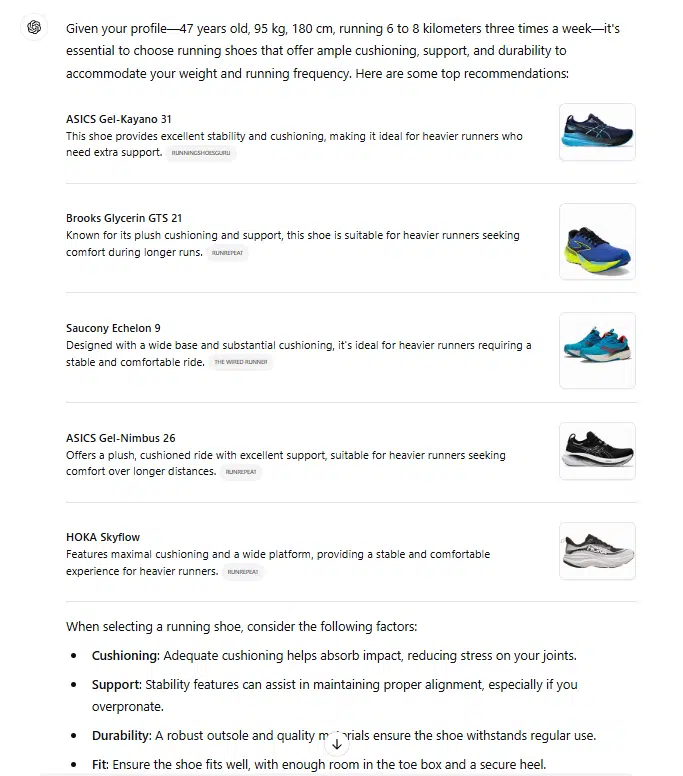
Les sources citées proviennent exclusivement de contenus informatifs, tels que des tests, des critiques et des classements, plutôt que de pages de commerce en ligne, comme des fiches produits ou des catégories.
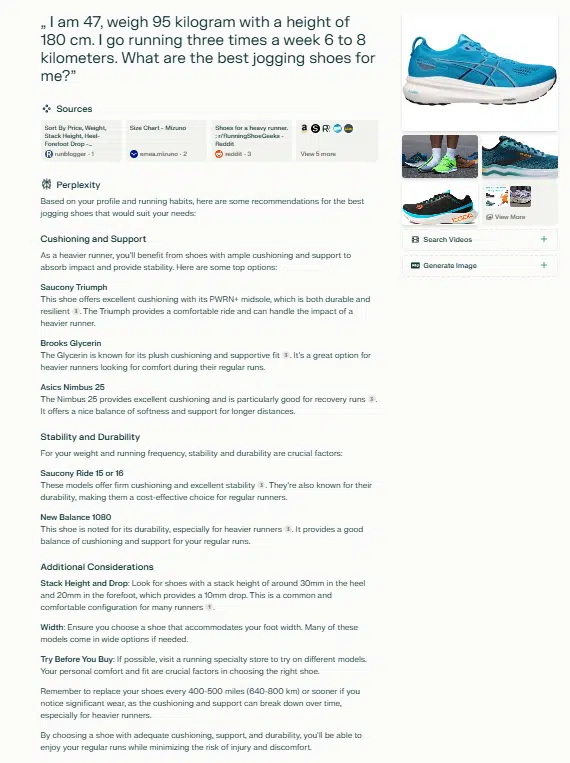
Perplexity
Perplexity prend en compte l’attribut du poids et en déduit un contexte de surpoids à partir des sources référencées.
Les sources incluent des contenus informatifs tels que des tests, des critiques, des classements, ainsi que des pages de commerce en ligne classiques.
Gemini
Gemini ne fournit pas directement les sources dans ses résultats. Toutefois, une analyse plus approfondie montre qu’il prend également en compte les contextes d’âge et de poids.
Sortie Gemini – invitation pour les meilleures chaussures de course
Sources Gemini – invitation pour choisir les meilleures chaussures de course
Chaque LLM majeur recommande des produits différents, mais une chaussure est systématiquement suggérée par les quatre systèmes d’IA testés.

Chaque LLM majeur propose des produits différents, mais une chaussure est systématiquement recommandée par les quatre systèmes d’IA testés.
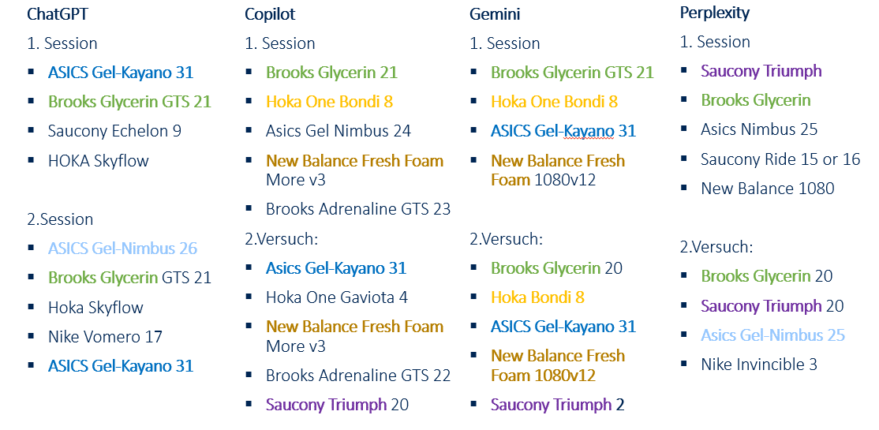
Tous les systèmes montrent une certaine créativité, en suggérant des produits différents lors de sessions variées. Copilot, Perplexity et ChatGPT privilégient des sources non commerciales, comme des sites de critiques ou des pages de tests, conformément à l’objectif de l’invite.
Claude, bien qu’il propose des modèles de chaussures, repose uniquement sur ses données d’entraînement initiales, sans accès à des données en temps réel ou à un système de récupération.

Chaque LLM a son propre processus de sélection des sources et du contenu, rendant le défi GEO plus complexe. Les recommandations sont influencées par la fréquence des cooccurrences et le contexte, ce qui augmente la probabilité de certains jetons lors du décodage.
Sélection des sources et informations pour une génération augmentée par récupération
GEO met l’accent sur le positionnement stratégique des produits, des marques et du contenu dans les ensembles de données utilisés pour entraîner les LLM. Comprendre en détail le processus de formation de ces modèles est crucial pour repérer les opportunités d’intégration.
Les éléments présentés ci-dessous proviennent d’études, de brevets, de publications scientifiques, de recherches sur l’EEAT et d’analyses personnelles. Les principales questions soulevées sont :
- Quelle est l’influence des systèmes de récupération dans le processus de RAG (Retrieval-Augmented Generation) ?
- Quel est le rôle des données de formation initiales ?
- Quels autres facteurs peuvent influencer les résultats ?
Des travaux récents, notamment sur la sélection des sources pour des outils comme AI Overviews, Perplexity et Copilot, mettent en lumière des recoupements significatifs dans les sources utilisées.
Par exemple, les analyses menées par Rich Sanger, Authoritas et Surfer montrent que les aperçus générés par Google AI affichent un chevauchement d’environ 50 % dans leur sélection de sources.
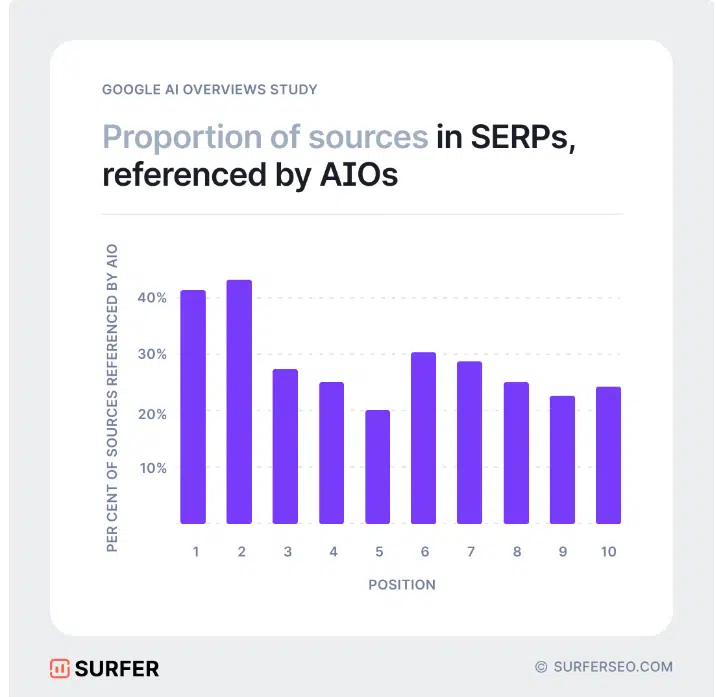
Analyse des marges de fluctuation et de l’impact des systèmes de récupération
La marge de fluctuation dans les chevauchements des études reste importante. Début 2024, le taux de chevauchement s’élevait à environ 15 %, bien qu’il ait atteint jusqu’à 99 % dans certaines analyses.
Les systèmes de récupération semblent influencer près de 50 % des résultats des aperçus générés par l’IA, indiquant des expérimentations en cours visant à optimiser les performances. Ces observations corroborent les critiques sur la qualité variable des réponses produites par ces systèmes.
La sélection des sources utilisées dans les réponses IA révèle des opportunités stratégiques pour positionner des marques ou des produits de manière contextuellement pertinente. Cependant, il est crucial de distinguer entre :
- Les sources de données utilisées pour la formation initiale des modèles, qui façonnent leur compréhension de base.
- Les sources ajoutées pour des sujets spécifiques, intégrées au cours du processus de génération augmentée par récupération (RAG).
L’examen du processus de formation des modèles éclaire ces distinctions. Par exemple, Gemini, le modèle multimodal de grande taille de Google, traite des données diversifiées, telles que du texte, des images, de l’audio, des vidéos et du code. Il utilise pour sa formation des documents Web, des livres, du code et du contenu multimédia, lui permettant de gérer des tâches complexes avec efficacité.
Enfin, les analyses des aperçus IA et des sources les plus souvent référencées offrent un aperçu précieux des indices et du Knowledge Graph utilisés par Google lors de la pré-formation des modèles. Cela ouvre la voie à des stratégies d’alignement pour inclure un contenu pertinent.
Dans le processus RAG, des sources spécialisées par domaine sont intégrées afin d’enrichir la pertinence contextuelle des réponses.
Une caractéristique majeure de Gemini réside dans l’utilisation d’une architecture de mélange d’experts (MoE). Contrairement aux transformateurs classiques, qui reposent sur un unique réseau neuronal, un modèle MoE est composé de réseaux « experts » plus petits et spécialisés. Ce modèle active de manière sélective les chemins experts les plus pertinents en fonction des données d’entrée, ce qui optimise l’efficacité et les performances du système. Il est probable que le processus RAG soit intégré dans cette architecture.
Développé par Google, Gemini passe par plusieurs étapes de formation, en utilisant des données publiques accessibles et des techniques avancées pour maximiser la pertinence et la précision du contenu généré :
Pré-formation
Comme d’autres grands modèles linguistiques (LLM), Gemini est d’abord pré-entraîné sur une variété de sources de données publiques. Google applique différents filtres pour assurer la qualité des données et éviter les contenus indésirables. Cette phase implique également une sélection souple de mots probables, permettant au modèle de générer des réponses plus créatives et adaptées au contexte.
Réglage fin supervisé (SFT)
Après la pré-formation, le modèle est affiné à l’aide d’exemples de haute qualité, soit créés par des experts, soit générés par d’autres modèles puis révisés par des spécialistes. Ce processus est similaire à l’apprentissage d’une bonne structure textuelle en observant des exemples de textes bien rédigés.
Apprentissage par renforcement à partir du feedback humain (RLHF)
Le modèle est ensuite perfectionné grâce à des évaluations humaines. Un système de récompense basé sur les préférences des utilisateurs aide Gemini à reconnaître et à apprendre les styles et types de contenu de réponse préférés.
Extensions et augmentation par récupération
Gemini peut rechercher des données externes, telles que celles provenant de Google Search, Maps, YouTube ou d’autres extensions spécifiques, afin d’enrichir les réponses avec des informations contextuelles actualisées. Par exemple, pour répondre à des questions sur la météo ou l’actualité, Gemini peut interroger directement Google Search pour trouver des informations fiables et récentes, puis les intégrer dans sa réponse.
Le modèle effectue un filtrage des résultats de recherche pour n’inclure que les informations les plus pertinentes en fonction du contexte de la requête. Par exemple, pour une question technique, il privilégiera des résultats scientifiques ou techniques plutôt que des informations générales disponibles sur le web.
Gemini combine les données récupérées avec ses connaissances internes pour générer une réponse optimisée. Ce processus comprend la création d’une réponse structurée de manière logique et lisible, après un examen final visant à garantir qu’elle respecte les normes de qualité de Google et ne contient pas de contenu inapproprié. Ce contrôle de qualité est renforcé par un classement qui privilégie les réponses les plus pertinentes. Le modèle présente ensuite à l’utilisateur la version la mieux classée.
Retours utilisateurs et optimisation continue
Google prend en compte en permanence les retours des utilisateurs et des experts pour affiner le modèle et corriger ses éventuelles faiblesses. Une possibilité envisagée est que les applications d’IA puissent accéder aux systèmes de recherche existants et intégrer leurs résultats.
Certaines études suggèrent qu’un bon classement dans les moteurs de recherche augmente la probabilité qu’une source soit citée dans les applications d’IA qui y sont connectées. Cependant, comme l’ont montré les analyses, les chevauchements actuels ne révèlent pas encore de lien clair entre les classements les plus élevés et les sources utilisées.
Un autre critère semble influencer le choix des sources : l’approche de Google privilégie le respect des normes de qualité lors de la sélection des sources pour la pré-formation et le processus RAG. De plus, l’utilisation de classificateurs est également citée comme un facteur déterminant dans ce processus.

Lors de la dénomination des classificateurs, un lien peut être établi avec le concept d’EEAT, où des classificateurs de qualité jouent également un rôle clé.
Les informations fournies par Google sur la post-formation mentionnent également l’utilisation d’EEAT pour classifier les sources en fonction de leur qualité.

La mention des évaluateurs fait référence au rôle des évaluateurs de qualité dans l’évaluation de l’EEAT.

Les classements dans la plupart des moteurs de recherche dépendent de la pertinence et de la qualité des informations, tant au niveau du document, du domaine que de l’auteur ou de l’entité source.
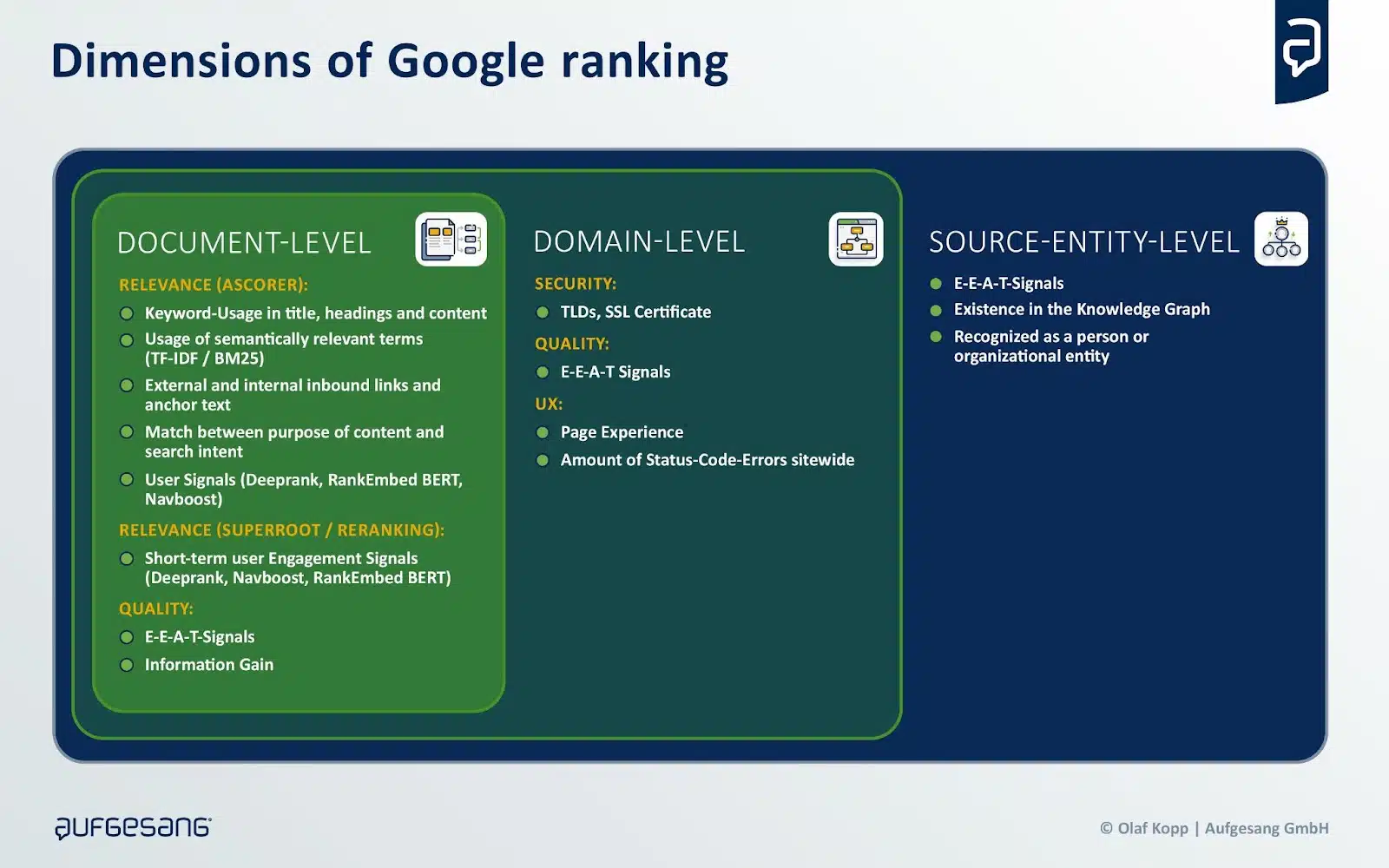
Les sources sont souvent choisies non seulement en fonction de leur pertinence, mais aussi en fonction de leur qualité au niveau du domaine et de l’entité source.
Cela peut s’expliquer par le fait que des requêtes plus complexes doivent être réécrites en arrière-plan pour générer des requêtes de recherche appropriées destinées à interroger les classements. Bien que la pertinence varie selon la requête, la qualité reste un critère constant.
Cette distinction aide à comprendre la faible corrélation entre les classements dans les moteurs de recherche et les sources référencées par l’IA générative, et pourquoi des sources de moindre rang peuvent parfois être incluses.
Pour évaluer la qualité, des moteurs de recherche comme Google et Bing utilisent des classificateurs, notamment le framework EEAT de Google. Google précise que l’EEAT peut varier en fonction du domaine, nécessitant ainsi des stratégies adaptées à chaque sujet, en particulier dans les stratégies GEO.
Les sources utilisées diffèrent selon le secteur ou le sujet, avec des plateformes comme Wikipédia, Reddit et Amazon jouant des rôles variés, comme l’indique une étude de BrightEdge.
Ainsi, les facteurs spécifiques à l’industrie et au sujet doivent être pris en compte dans les stratégies de positionnement.
Approches tactiques et stratégiques pour LLMO / GEO
Comme mentionné précédemment, il n’existe pas encore de preuve tangible concernant l’influence directe sur les résultats de l’IA générative. Les opérateurs des plateformes semblent eux-mêmes incertains quant à la manière de qualifier les sources choisies pendant le processus RAG.
Ces éléments soulignent l’importance d’identifier les domaines sur lesquels les efforts d’optimisation doivent se concentrer, en particulier en déterminant quelles sources sont suffisamment fiables et pertinentes pour être priorisées.
Le défi suivant est de comprendre comment vous positionner comme l’une de ces sources de référence.
Le document de recherche intitulé « GEO : Generative Engine Optimization » a introduit le concept de GEO, en explorant comment les résultats de l’IA générative peuvent être influencés et en identifiant les facteurs clés responsables de cette influence.
Selon l’étude, la visibilité et l’efficacité du GEO peuvent être optimisées par les éléments suivants :
- Autorité dans l’écriture : Elle améliore les performances, surtout sur des questions de débat ou des requêtes dans des contextes historiques. Une écriture plus persuasive a en effet davantage de valeur dans ces situations où l’argumentation joue un rôle central.
- Citations (références de sources) : Elles sont particulièrement utiles pour les questions factuelles, car elles fournissent une source de vérification des informations, renforçant ainsi la crédibilité de la réponse générée.
- Ajout statistique : Très efficace dans des domaines comme le droit, le gouvernement ou l’opinion, l’intégration de statistiques pertinentes dans le contenu des pages Web peut améliorer la visibilité dans des contextes spécifiques.
- Citations directes : Elles ont un impact plus significatif dans des domaines comme les sciences sociales, l’histoire ou les récits personnels, car elles ajoutent de l’authenticité et de la profondeur aux réponses.
Ces facteurs varient en fonction du domaine, ce qui suggère que l’intégration de personnalisation ciblée et spécifique à chaque secteur est essentielle pour augmenter la visibilité des pages Web.
Les mesures tactiques suivantes pour GEO et LLMO peuvent être dérivées de ce document :
- Utiliser des sources citables : Intégrez des sources fiables et vérifiables à votre contenu pour renforcer la crédibilité et l’authenticité, surtout pour les informations factuelles.
- Ajouter des statistiques : Intégrez des statistiques pertinentes pour soutenir vos arguments, en particulier dans des domaines comme le droit, le gouvernement ou les questions d’opinion.
- Utiliser des citations : Enrichissez le contenu avec des citations dans des domaines tels que les sciences sociales, l’histoire ou les explications, car elles ajoutent de la profondeur et de l’authenticité.
- Optimisation spécifique au domaine : Prenez en compte les particularités de votre secteur lors de l’optimisation, car l’efficacité des techniques GEO peut varier selon le domaine.
- Focalisez-vous sur la qualité du contenu : Créez du contenu de haute qualité, pertinent et informatif, qui répond aux besoins réels des utilisateurs.
Par ailleurs, certaines pratiques tactiques doivent être évitées :
- Éviter le bourrage de mots-clés : Le bourrage de mots-clés traditionnel n’apporte généralement pas d’améliorations significatives dans les résultats générés par l’IA et doit être évité.
- Ne pas ignorer le contexte : Évitez de générer du contenu qui soit déconnecté du sujet ou qui n’apporte aucune valeur ajoutée à l’utilisateur.
- Ne pas négliger l’intention de l’utilisateur : Assurez-vous que votre contenu réponde vraiment aux attentes et besoins des utilisateurs en fonction de leurs requêtes de recherche.
D’après les recherches de BrightEdge, voici les considérations stratégiques à prendre en compte :
Différents impacts des backlinks et des co-citations
Les aperçus de l’IA et Perplexity privilégient des ensembles de domaines distincts en fonction du secteur.
Dans les domaines de la santé et de l’éducation, ces plateformes privilégient des sources fiables comme mayoclinic.org et coursera.com, ce qui en fait des cibles clés pour des stratégies SEO efficaces.
En revanche, dans les secteurs du commerce électronique et de la finance, Perplexity privilégie des sites comme reddit.com, yahoo.com et marketwatch.com. Adapter vos efforts SEO à ces préférences en utilisant les backlinks et les co-citations peut améliorer significativement les performances.
Stratégies sur mesure pour la recherche basée sur l’IA
Les stratégies de recherche basées sur l’IA doivent être adaptées à chaque secteur.
Par exemple, la préférence de Perplexity pour reddit.com montre l’importance des informations communautaires dans le commerce électronique, tandis qu’AI Overviews privilégie des sites comme consumerreports.org et quora.com pour les critiques et les questions-réponses.
Les spécialistes du marketing et du référencement doivent aligner leurs stratégies de contenu sur ces tendances, en créant des critiques détaillées de produits ou en soutenant les forums de questions-réponses pour les marques de commerce électronique.
Anticiper les changements dans le paysage des citations
Les référenceurs doivent surveiller de près les sites préférés de Perplexity, notamment l’influence croissante de reddit.com pour le contenu communautaire.
Le partenariat de Google avec Reddit pourrait influencer les algorithmes de Perplexity, lui donnant davantage la priorité.
Les référenceurs doivent rester proactifs et ajuster leurs stratégies pour s’adapter aux évolutions des préférences de citation, assurant ainsi la pertinence et l’efficacité de leurs actions.
Technologie B2B
- Établissez une présence sur des sites d’autorité : Publiez sur des domaines réputés comme techtarget.com, ibm.com, microsoft.com et cloudflare.com, qui sont perçus comme des sources fiables.
- Exploitez la syndication de contenu : Profitez des plateformes établies pour accroître rapidement votre citation comme source fiable.
- Construisez votre autorité de domaine : À long terme, produisez un contenu de qualité pour établir une autorité durable, car la compétition pour les spots de syndication augmentera.
- Partenariats avec des plateformes clés : Collaborez activement avec les leaders du secteur et contribuez à leur contenu.
- Démontrez votre expertise : Affichez des certifications, des titres de compétences et des témoignages d’experts pour signaler votre fiabilité.
Commerce électronique
- Présence sur Amazon : Concentrez-vous sur Amazon, qui est une source privilégiée par Perplexity.
- Valorisez les avis produits : Mettez en avant les avis sur les produits et le contenu généré par les utilisateurs sur Amazon et d’autres plateformes pertinentes.
- Distributeurs et sites de comparaison : Diffusez des informations produits sur des plateformes de revendeurs établis et des sites de comparaison.
- Syndication et partenariats : Syndiquez du contenu sur des domaines fiables et établissez des partenariats avec des sites de confiance.
- Mise à jour régulière des informations produits : Assurez-vous que les descriptions de produits sont détaillées et à jour sur toutes les plateformes de vente.
- Engagez-vous sur des forums communautaires : Soyez actif sur des plateformes comme Reddit et d’autres portails spécialisés.
- Stratégie marketing équilibrée : Combinez une forte présence sur des plateformes externes avec le développement de votre propre autorité de domaine.
Formation continue
- Collaboration avec des sites d’autorité : Travaillez avec des sites comme coursera.org, usnews.com et bestcolleges.com pour créer des sources fiables.
- Contenu de qualité et actualisé : Créez du contenu bien structuré, actualisé et basé sur des connaissances spécialisées.
- Présence sur des plateformes communautaires : Soyez actif sur Reddit et d’autres forums pertinents, car le contenu communautaire devient essentiel.
- Optimisation de votre contenu : Utilisez une structure claire et des titres concis pour optimiser votre contenu pour les systèmes d’IA.
- Mettez en valeur les certifications et accréditations : Elles renforcent la crédibilité et la fiabilité de votre contenu.
Finance
- Présence sur des portails financiers fiables : Utilisez des plateformes comme yahoo.com et marketwatch.com, qui sont des sources privilégiées par les IA.
- Maintien des informations à jour : Assurez-vous que les informations financières sont précises et récentes sur les principales plateformes.
- Contenu de haute qualité et factuel : Créez du contenu vérifiable, étayé par des sources reconnues.
- Présence active sur Reddit : Engagez-vous dans des communautés financières pertinentes, car Reddit est de plus en plus prisé par les IA.
- Partenariats avec des médias financiers : Collaborez avec des médias financiers établis pour augmenter votre visibilité et crédibilité.
- Démonstration d’expertise : Affichez des connaissances spécialisées, certifications et témoignages d’experts.
Santé
- Lien vers des sources fiables : Intégrez des références vers des sites comme mayoclinic.org, nih.gov et medlineplus.gov.
- Intégration des tendances médicales : Mettez à jour régulièrement le contenu avec les dernières recherches médicales.
- Contenu bien documenté : Fournissez des informations médicales détaillées et étayées par des institutions officielles.
- Crédibilité et expertise : Mettez en avant les certifications et qualifications pour renforcer la fiabilité.
- Mise à jour régulière du contenu : Adaptez votre contenu en fonction des nouvelles découvertes médicales.
- Stratégie équilibrée : Utilisez une combinaison de contenu sur des plateformes de santé établies et le renforcement de votre propre autorité de domaine.
Assurance
- Utilisation de sources fiables : Publiez sur des sites réputés comme forbes.com et les sites .gov pour renforcer votre crédibilité.
- Exactitude des informations : Assurez-vous que toutes les informations sur les produits et services sont précises et actuelles.
- Syndication de contenu : Partagez votre contenu sur des plateformes comme Forbes pour être cité comme source fiable plus rapidement.
- Pertinence locale : Adaptez votre contenu aux marchés locaux et aux réglementations en vigueur dans le secteur de l’assurance.
Restaurants
- Présence sur des plateformes d’avis : Maintenez une forte présence sur Yelp, TripAdvisor, OpenTable et GrubHub.
- Avis et notes positives : Encouragez les clients à laisser des avis positifs et interagissez avec eux.
- Informations complètes : Assurez-vous que les informations sur les menus, horaires d’ouverture et photos sont complètes et actualisées.
- Engagement avec les communautés culinaires : Participez activement à des sites comme Eater.com et autres plateformes gastronomiques.
- Optimisation du référencement local : Effectuez un SEO local, car l’IA privilégie souvent la pertinence locale.
- Entrées sur Wikipédia : Maintenez des entrées Wikipédia complètes et bien tenues.
- Processus de réservation en ligne fluide : Offrez un service de réservation en ligne simple via des plateformes pertinentes.
Tourisme / Voyages
- Optimisation de la présence sur des plateformes de voyage : Créez un contenu attractif et optimisé pour TripAdvisor, Expedia, Kayak, Hotels.com et Booking.com.
- Contenu complet et authentique : Fournissez des guides de voyage, des conseils et des avis détaillés.
- Optimisation du processus de réservation : Assurez-vous que le processus de réservation est simple et convivial.
- SEO local : Intégrez une optimisation pour les recherches locales, car l’IA privilégie la localisation.
- Encouragez les avis sur les plateformes : Soyez actif sur les plateformes de voyage et encouragez les utilisateurs à laisser leurs avis.
- Collaborez avec des partenaires de confiance : Développez des partenariats avec des sites de voyages réputés pour accroître votre visibilité et crédibilité.
L’avenir de GEO : implications pour les marques
L’avenir de la GEO en particulier dans le cadre de la recherche alimentée par l’IA comme ChatGPT, marque une évolution importante pour les stratégies marketing des entreprises. Cela repose en grande partie sur la manière dont les comportements de recherche des consommateurs évoluent et sur la manière dont les entreprises exploitent les nouvelles technologies pour se positionner dans ces environnements.
Voici une synthèse des points clés de cette évolution et ce que cela signifie pour les marques :
1. L’importance de GEO et des IA génératives
- La montée de ChatGPT et Bing : Si ChatGPT devient une application dominante d’IA générative, s’assurer que votre marque est bien positionnée sur Microsoft Bing (qui alimente ChatGPT) pourrait devenir crucial pour influencer les applications d’IA. Cette évolution pourrait permettre à Bing de récupérer des parts de marché de Google.
2. Objectifs clés pour les entreprises :
- Médias propriétaires comme sources d’entraînement LLM : Les entreprises doivent établir une présence dans les médias propriétaires, en produisant des contenus qui respectent les principes EEAT (Expertise, Authoritativeness, Trustworthiness). Cela garantit que les informations fournies sont considérées comme fiables et sont utilisées dans le processus d’entraînement des LLM.
- Générer des mentions dans des médias réputés : Être cité dans des plateformes d’autorité est essentiel pour renforcer la perception de la marque par les IA et pour garantir une forte cooccurrence de la marque avec des attributs et entités pertinents dans ces médias.
- Produire du contenu optimisé pour les systèmes RAG : Créer du contenu de haute qualité qui se classe bien, qui est pris en compte dans les systèmes RAG (Retrieval-Augmented Generation), est un autre élément clé de l’optimisation pour l’IA.
3. Différence entre les marchés de niche et vastes marchés
- Marchés de niche : Sur ces marchés, il est plus facile de se positionner grâce à la moindre concurrence. Moins de cooccurrences sont nécessaires pour associer une marque à des entités spécifiques dans les systèmes LLM.
- Marchés vastes : Sur les marchés plus concurrentiels, où les marques ont déjà une forte présence, la tâche devient plus complexe. Ici, la gestion de la perception publique à grande échelle devient indispensable, impliquant des ressources considérables en relations publiques et marketing.
4. Le rôle du référencement traditionnel
- Bien que les stratégies GEO ou LLMO demandent des investissements plus conséquents, le référencement traditionnel peut toujours jouer un rôle clé dans la formation des modèles de LLM, à condition de produire un contenu de qualité, bien structuré et pertinent.
5. La gestion numérique de l’autorité
- Le concept de gestion numérique de l’autorité devient crucial pour les entreprises afin de se préparer à l’avenir. Cela implique de structurer les efforts en matière de relations publiques, de SEO, et de création de contenu pour s’assurer que la marque est perçue comme une source fiable et crédible, à la fois par les utilisateurs et par les IA.
6. Avantages pour les grandes marques
- Les grandes marques, avec leurs ressources en relations publiques et en marketing, bénéficieront probablement d’un avantage substantiel dans les classements des moteurs de recherche et dans les résultats des IA génératives. Leur capacité à générer de la visibilité et à renforcer la perception de la marque via des mentions dans des médias fiables leur permettra de mieux se positionner.
Conclusion :
Les entreprises doivent non seulement se concentrer sur le référencement traditionnel, mais aussi sur la cooccurrence de leur marque avec des entités et attributs pertinents dans des médias d’autorité. Pour réussir dans un monde dominé par l’IA générative, il sera crucial d’optimiser les relations dans des plateformes reconnues et d’investir dans la gestion de l’autorité numérique pour influencer la perception publique à grande échelle. 😊
Cela signifie que les marques devront adapter leurs stratégies pour s’assurer qu’elles sont bien positionnées à la fois dans les moteurs de recherche traditionnels et dans les résultats générés par l’IA, tout en anticipant une évolution rapide du paysage numérique.
SEO sur les LLMs : Les optimisations à mettre en place
L’optimisation SEO sur les LLMs consiste à se rendre visible sur les nouveaux moteurs de recherche.
Que ce soit ChatGPT, Perplexity, Microsoft Copilot ou Gemini, chaque grand modèle de langage utilise une base de données pour fournir des réponses à l’internaute. À quelques exceptions près, cette database est tout simplement constituée du vaste univers d’internet. Autrement dit, les LLMs puisent leurs connaissances depuis les centaines de milliers de sites présents sur le web. Parmi lesquels se trouve sans doute le vôtre.
Certains modèles de langage utilisent le contenu sans préciser la source à l’internaute. Mais par souci de transparence, ils sont de plus en plus nombreux à citer la provenance des informations transmises. Certains sites particulièrement pertinents parviennent ainsi à se rendre visibles sur les outils LLM. Les internautes qui souhaitent en savoir plus peuvent alors cliquer sur le lien du site et accéder à son contenu.
Mais pour cela, encore faut-il maîtriser l’optimisation SEO sur les LLMs.
Comment devenir visible sur les moteurs de recherche LLMs ?
Découvrez nos astuces pour vous faire démarquer et vous rendre visible sur les moteurs de recherche nouvelle génération.
1 – Comprendre les modèles d’intelligence artificielle
Avant de s’engager dans l’optimisation de l’IA générative, il est essentiel de bien comprendre les technologies qui se cachent derrière les LLM. Cela vous permettra d’identifier le potentiel futur du référencement.
Ces assistants d’intelligence artificielle vont bien au-delà de la simple correspondance de texte. Autrement dit, ils ne se contentent pas d’extraire des informations à partir de documents existants. À la place, ils génèrent des réponses complètes, précises, pertinentes, nuancées et contextuellement riches.
Cela est possible grâce à leurs capacités de compréhension et de raisonnement linguistiques (traitement du langage naturel – NLP).
Attention toutefois : les LLM ne “comprennent” pas les requêtes des internautes, pas au sens humain du terme. Ils traitent les données de manière statistique.
2 – Fournir du contenu de qualité via le SEO
En soi, les grands principes du SEO ne changent pas. Il faut toujours soigner la technique de son site internet, booster la popularité avec une stratégie de netlinking et produire du contenu de qualité.
Mais ici, les exigences de qualité sont encore plus élevées qu’avant. Le SEO sur les LLMs ne vont pas chercher des informations auprès de sites qui disent tous la même chose, avec des tournures de phrases différentes. À la place, les IA génératives veulent du contenu unique et précis, avec des exemples concrets, des chiffres, des infographies, des études de cas, des sources explicites…
Finalement, plus votre contenu est généraliste, moins il a de chances de répondre aux exigences de l’optimisation de l’IA générative.
3 – Définir une stratégie de marque SEO
Soucieux de la pertinence de leurs sources, les grands modèles de langage ne vont pas mettre en avant des sites inconnus aux bataillons. Ils privilégient les sites ayant déjà une certaine autorité et popularité. Cela passe évidemment par la stratégie de netlinking, mais plus seulement. Désormais, il faut définir une véritable identité de marque : pourquoi êtes-vous unique ?
Finalement, l’optimisation de l’IA générative va encore plus loin que le SEO traditionnel.
Attention, à l’heure actuelle, il n’existe pas encore de méthode d’optimisation de l’IA générative éprouvée et approuvée. D’ailleurs, en réponse à une même requête, chaque modèle présente différents résultats. Ce n’est donc pas une science exacte à 100 %.
Cela dit, ces grands principes maximisent vos chances d’apparaître sur les nouveaux moteurs de recherches.
À l’approche des achats de Noël, l’optimisation SEO pour les LLMs devient essentielle. Pour capter l’attention des consommateurs sur des plateformes comme SearchGPT, les marques doivent ajuster leurs stratégies SEO en intégrant des optimisations adaptées à l’IA générative. En se concentrant sur la qualité du contenu, les cooccurrences pertinentes et la visibilité sur des sources fiables, les entreprises pourront améliorer leur positionnement pendant cette période cruciale.
Les achats de Noël sur les SearchGPT : les optimisations SEO à prévoir
Pour beaucoup, les achats de Noël ne sont pas toujours une partie de plaisir. Alors quand un outil basé sur l’intelligence artificielle offre la possibilité de délivrer une liste d’idées adaptées à une demande relativement précise, incluant le budget fixé et des informations majeurs sur le receveur, il serait dommage de s’en priver. Si cette habitude n’est, pour le moment, pas adoptée par tous les offreurs, qui privilégient encore très majoritairement le moteur de recherche de Google, cela reste une tendance de plus en plus préoccupante pour les marques, qui voient un intérêt croissant à figurer parmi les premières options proposées par les plateformes.
Pour les annonceurs, il est donc important de suivre ses propres mentions au sein des plateformes de recherche basées sur l’IA, et de mettre en place une stratégie SEO efficace pour renforcer sa présence en ligne. Une mission bien plus complexe qu’elle ne peut l’être pour les moteurs de recherches. Sur des plateformes comme ChatGPT, la recherche est conversationnelle, ce qui rend les résultats plus contextuels et personnalisés, et donc, de fait, plus difficile à catégoriser.
Profound : un outil SEO à maitriser pour sa stratégie des Fêtes
Ainsi, des outils SEO ont récemment fait leur apparition afin de permettre aux marques d’obtenir des informations concernant leurs mentions au sein des conversations. C’est notamment le cas de Profound qui apparaît comme l’un des leaders sur ce marché. Cet outil parvient à générer plusieurs conversations en utilisant des variantes pour les exécuter plusieurs fois, de sorte à identifier les marques les mieux recommandées par les différentes plateformes. À travers cette technologie, les marques peuvent donc en savoir davantage sur leur propre visibilité au sein des réponses données par les plateformes et adapter votre stratégie SEO en fonction et cibler les mots-clés pertinents.
À partir d’une étude effectuée sur les vendeurs de jouets, le site Search Engine Land a dévoilé les quelques informations pertinentes révélées par Profound. L’outil d’analyse peut notamment fournir un classement de la visibilité des marques sur une même thématique, à travers les conversations générées sur les plateformes de recherches basées sur l’intelligence artificielle. Le pourcentage présenté correspond donc au taux de réponses de l’IA qui mentionnent la marque en question :
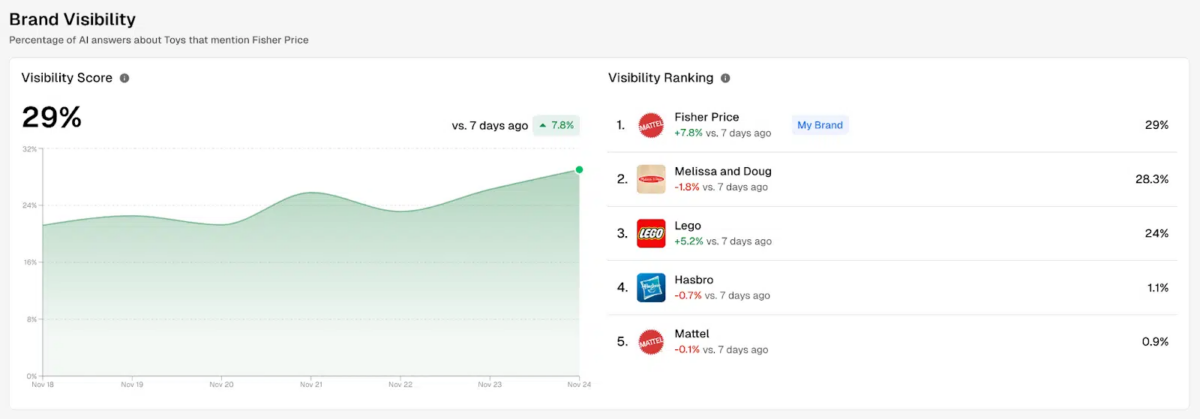
À noter que la visibilité de chaque marque peut être différente selon la plateforme, dans la mesure où les modèles utilisés ne sont pas les mêmes :
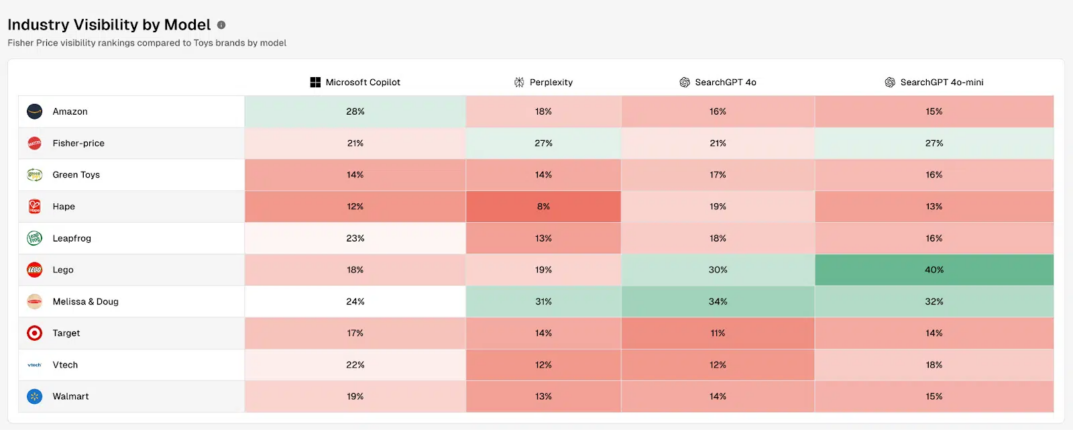
Il est également possible de déterminer la place de chaque marque concurrente pour chacun des différents thèmes fournis à Profound :

Les relations numériques : le secret d’une stratégie SEO qui fonctionne sur les SearchGPT
Mais alors, comment les marques citées plus haut sont-elles devenues des références dans leur domaine ? Tout est une question de SEO, il convient alors de s’intéresser aux sources utilisées par l’IA pour fournir ses réponses.
Par exemple, pour le sujet des jouets, ce sont principalement les contenus du site TinyBeans, destinés aux parents, qui a eu le plus d’influence dans les résultats. En d’autres termes, ce site est considéré comme l’autorité principale en matière de contenus liés aux jouets, d’après les différents modèles de recherches basés sur l’intelligence artificielle.
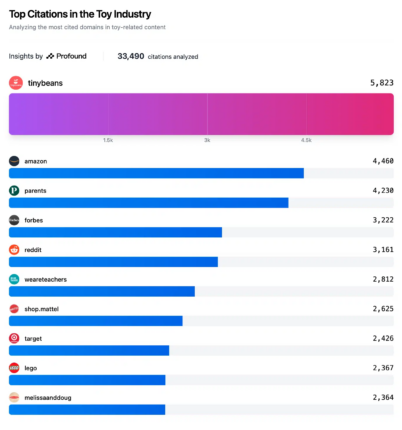
Parmi les quatre premiers résultats, on retrouve pas moins de trois éditeurs de contenus, à savoir TinyBeans, Forbes et Parents. À l’inverse, les contenus fournis par les plus grandes marques de ce marché, comme Lego ou Melissa & Doug n’apparaissent qu’au pied du top 10.
Si l’analyse effectuée sur l’outil Profound ne peut suffire pour tirer une conclusion définitive sur le fonctionnement du référencement, une tendance semble clairement se dessiner. Contrairement aux moteurs de recherches comme Google, qui favorisent la qualité du contenu fourni par la marque pour la mettre en avant sur les pages de résultats, c’est davantage le contenu tiers qui semble primer sur les plateformes SearchGPT.
Ainsi, pour qu’une marque soit performante dans les résultats délivrés par ces plateformes, il faut avant tout qu’elle soit mise en avant au sein des sources reconnues. En plus des préconisations SEO déjà évoquées, les marques ont donc tout intérêt à mettre en place des stratégies de relations publiques numériques, et travailler en collaboration avec des éditeurs de contenus de qualité, afin de prendre une longueur d’avance sur leurs concurrents.
Vous souhaitez vous rendre visible sur les moteurs d’IA générative, n’hésitez pas à contacter notre agence SEO pour optimiser votre site.
Vous êtes dans le secteur Plomberie & Artisans ?
Multipliez vos interventions locales avec des campagnes ciblées. Découvrez notre méthode dédiée à votre profession.
Voir la solution Plomberie & Artisans